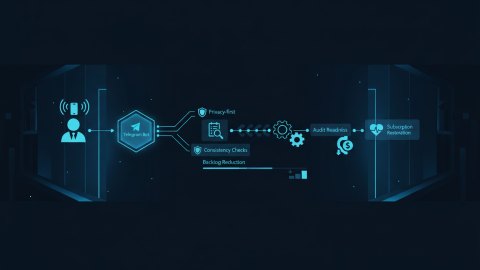
В B2B SaaS критически важно обеспечивать стабильность и надежность. Edge-cases в биллинге и лимитах могут существенно влиять на удержание клиентов. Для решения этой задачи рассмотрим подход, основанный на AI-observability, который позволяет автоматизировать маршрутизацию инцидентов и стабилизировать критические процессы.
Задача: стабилизировать edge-cases биллинга и лимитов. Ограничение: Рaспределенная ownership-модель без общих runbook. Business outcome: Улучшение удержания клиентов за счет стабильности продукта.

Data Science Подход к AI-Observability
Data science подход в AI-observability заключается в использовании машинного обучения для анализа данных мониторинга, выявления аномалий и автоматизации рутинных задач. Рассмотрим этапы этого подхода.
Извлечение Фич
Для начала необходимо определить, какие данные мониторинга будут использоваться для обучения модели. Важно выделить релевантные фичи, характеризующие состояние системы. Примеры фич:
- Использование ресурсов (CPU, память, дисковое пространство).
- Задержка API.
- Частота ошибок (5xx, 4xx).
- Объем трафика.
- Количество активных пользователей.
- Данные о биллинге (количество списаний, сумма списаний, и т.д.).
- Сведения о лимитах (достигнутый процент лимита, оставшееся время до превышения лимита).
Для биллинга особенно важны фичи, которые могут указывать на потенциальные проблемы, такие как резкие изменения в объеме потребления ресурсов или необычные паттерны использования API.
Обучение Модели
Для обучения модели можно использовать различные алгоритмы машинного обучения, например:
- Классификация: для определения типа инцидента (например, проблемы с биллингом, превышение лимита, проблемы с производительностью).
- Регрессия: для прогнозирования будущих значений фич (например, прогнозирование использования ресурсов для предотвращения превышения лимитов).
- Детекция аномалий: для выявления необычных паттернов поведения системы.
Выбор алгоритма зависит от конкретной задачи. Например, если нужно классифицировать инциденты по типу, можно использовать алгоритмы классификации, такие как Random Forest или Support Vector Machines (SVM). Для задач прогнозирования можно использовать временные ряды и алгоритмы ARIMA. Для обнаружения аномалий - Isolation Forest или One-Class SVM. Подробнее об аномалиях и их мониторинге можно узнать в статье Карта зависимостей модулей: аудит асинхронных интеграций для безопасной миграции.
Метрики
После обучения модели необходимо оценить ее качество. Для этого используются различные метрики. Примеры метрик для задачи классификации:
- Accuracy: доля правильно классифицированных инцидентов.
- Precision: доля инцидентов, которые были правильно классифицированы как проблемы с биллингом, среди всех инцидентов, классифицированных как проблемы с биллингом.
- Recall: доля инцидентов, которые на самом деле являются проблемами с биллингом, и были правильно классифицированы как проблемы с биллингом.
- F1-score: гармоническое среднее между precision и recall.
Важно учитывать баланс между precision и recall. Если важна минимизация ложных срабатываний (то есть классификации нормальных инцидентов как проблем с биллингом), нужно стремиться к высокому precision. Если важна минимизация пропущенных инцидентов (то есть классификации проблем с биллингом как нормальных инцидентов), нужно стремиться к высокому recall.
Детект Дрейфа
Со временем поведение системы может меняться, что приводит к ухудшению качества модели. Это явление называется дрейфом данных (data drift) или дрейфом модели (model drift). Для обнаружения дрейфа необходимо регулярно мониторить метрики качества модели и сравнивать их с исходными значениями. Если метрики значительно ухудшились, необходимо переобучить модель на новых данных.
Также полезно мониторить распределение входных фич и сравнивать его с распределением фич, на которых модель была обучена. Если распределения значительно отличаются, это также может указывать на дрейф данных.
AI-Модерация и Маршрутизация Обращений
После выявления инцидента с использованием AI, необходимо его маршрутизировать ответственной команде. Важно автоматизировать этот процесс, чтобы ускорить решение проблемы. Примеры:
- Инциденты, связанные с биллингом, автоматически направляются в команду биллинга.
- Инциденты, связанные с превышением лимитов, направляются в команду поддержки аккаунтов.
Этот процесс важен для триажа заявок и корректной SLA-scorecard, как это реализовано в Enterprise-ready HR Telegram-бот: архитектура триажа заявок и SLA-scorecard.
Итоги
AI-observability позволяет автоматизировать обнаружение и маршрутизацию инцидентов, связанных с биллингом и лимитами, что приводит к повышению стабильности системы и улучшению удержания клиентов. Важно правильно выбрать фичи, алгоритмы машинного обучения и метрики качества модели, а также мониторить дрейф данных и регулярно переобучать модель. Такой подход позволяет перейти к проактивной архитектуре безопасности.
Для построения и сопровождения подобных решений требуется экспертиза в различных областях. Обратитесь к нам, если вам нужна помощь в проектировании и внедрении AI-observability для вашей B2B SaaS платформы.