Представьте себе финтех-платформу, которая обрабатывает миллионы транзакций в день, интегрируя различные платежные системы и банки. Сбои могут привести к прямым финансовым потерям, штрафам и потере доверия клиентов. Традиционные подходы к обеспечению отказоустойчивости, такие как репликация данных и балансировка нагрузки, не всегда достаточны для защиты от масштабных инцидентов – от проблем с сетью до поломок оборудования.
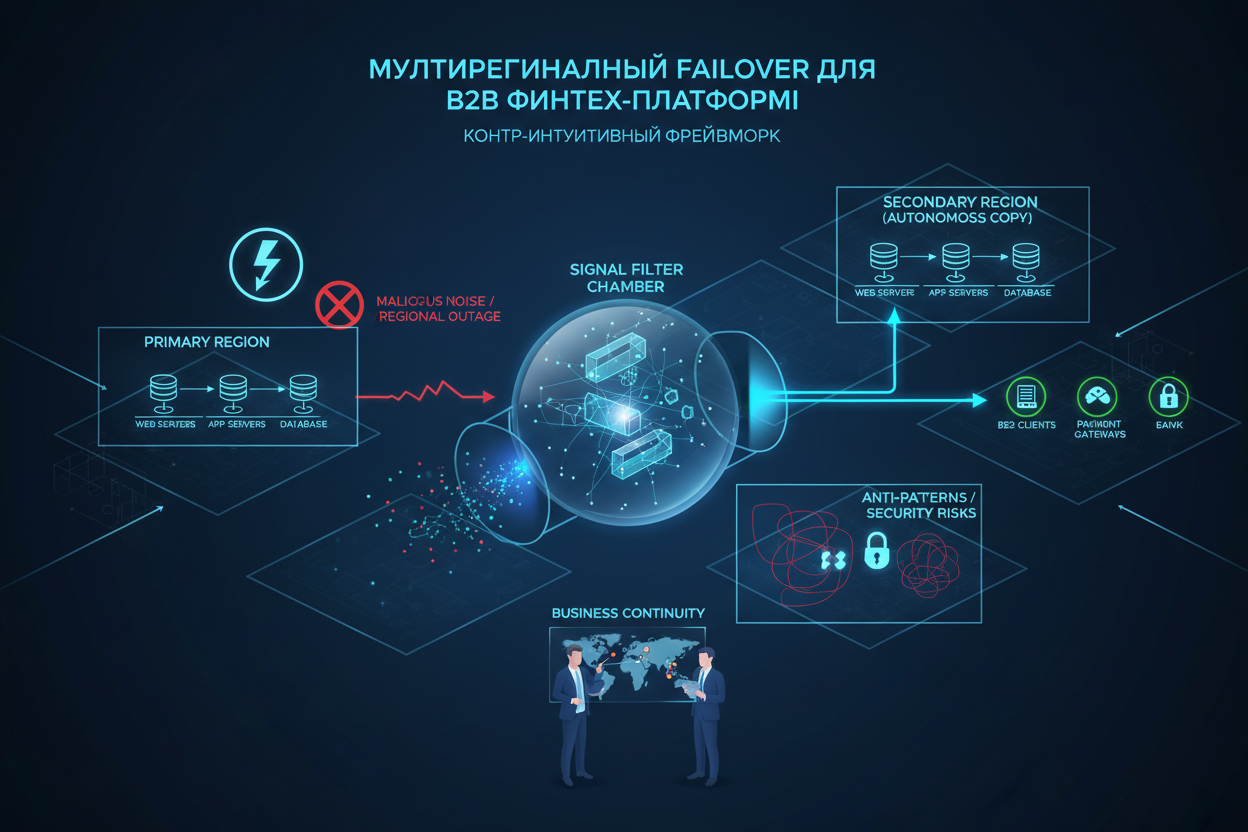
Исходное состояние: Локализованная инфраструктура
Изначально инфраструктура платформы была развернута в одном регионе с использованием классической трехуровневой архитектуры: веб-серверы, серверы приложений и база данных. Репликация данных на резервный сайт в том же регионе использовалась для защиты от незначительных сбоев. Однако такой подход не учитывал более серьезные сценарии.
Инцидент: Отключение электроэнергии в регионе
В один из дней произошла крупная авария на электростанции, которая привела к полному отключению электроэнергии в регионе, где располагалась основная инфраструктура платформы. Несмотря на наличие резервного сайта, он также оказался недоступен, так как зависел от той же энергосети. В результате платформа полностью прекратила работу, что привело к значительным финансовым потерям и негативно сказалось на репутации компании.
Анализ геосигналов и контр-интуитивное решение
После анализа инцидента стало очевидно, что необходимо разрабатывать более устойчивое решение, которое смогло бы выдерживать региональные сбои. Контр-интуитивный подход заключался в том, чтобы не просто продублировать инфраструктуру в другом регионе, а создать полностью независимую копию платформы, способную работать автономно.
Гео-распределение инфраструктуры
Принято решение о развертывании идентичной инфраструктуры в другом географическом регионе, максимально удаленном от основного. Это позволило минимизировать риск одновременного выхода из строя обеих инфраструктур в результате стихийных бедствий или других региональных событий.
Синхронизация данных
Вместо традиционной асинхронной репликации базы данных было решено использовать более надежный, хотя и более сложный, механизм синхронной репликации. Это гарантировало, что данные в обоих регионах всегда будут актуальны, что критически важно для финтех-платформы.
Автоматическое переключение трафика
Для обеспечения автоматического переключения трафика между регионами была разработана система мониторинга, которая отслеживала состояние обеих инфраструктур. В случае обнаружения сбоя в основном регионе, система автоматически перенаправляла трафик на резервный регион. Чтобы больше узнать о комплексном подходе к мониторингу, ознакомьтесь со статьей SEO-Observability Runbook: Управление SLA и эскалацией инцидентов в контентной платформе.
Исправление: Фреймворк Мультирегионального Failover
Для реализации мультирегионального failover был разработан специальный фреймворк, включающий следующие компоненты:
- Гео-распределенная база данных: Использование базы данных с поддержкой синхронной репликации между регионами.
- Автоматическое переключение трафика: Разработка системы мониторинга и переключения трафика на основе DNS или балансировщиков нагрузки.
- Идемпотентные транзакции: Обеспечение идемпотентности транзакций для предотвращения дублирования операций при переключении между регионами. Миграция API в Multi-Tenant SaaS также может помочь с разработкой идемпотентных транзакций.
- Независимость компонент: Инфраструктура для каждого компонента в каждом регионе должна быть независимой.
Чек-лист для внедрения фреймворка:
- Определите критически важные компоненты платформы, требующие защиты от региональных сбоев.
- Выберите географические регионы для развертывания резервной инфраструктуры.
- Настройте синхронную репликацию базы данных между регионами.
- Разработайте систему мониторинга и автоматического переключения трафика.
- Протестируйте failover на тестовом окружении.
- Обеспечьте идемпотентность транзакций.
- Проведите обучение персонала работе с фреймворком failover.
Антипаттерны:
- Использование асинхронной репликации базы данных, что может привести к потере данных при переключении.
- Зависимость резервной инфраструктуры от основной, например, использование общей сети или системы аутентификации.
- Ручное переключение трафика, что увеличивает время простоя.
- Отсутствие идемпотентности транзакций, что может привести к дублированию операций.
Пример конфигурации балансировщика нагрузки (упрощенный):
health_check:
path: /health
interval: 5s
timeout: 2s
backends:
region_a:
servers:
- host: app-server-a1.example.com
- host: app-server-a2.example.com
region_b:
servers:
- host: app-server-b1.example.com
- host: app-server-b2.example.com
failover:
region_a:
priority: 1
region_b:
priority: 2
Этот пример демонстрирует базовую конфигурацию, где `region_a` имеет более высокий приоритет. Балансировщик нагрузки будет автоматически перенаправлять трафик в `region_b`, если health check в `region_a` не проходит.
Инсайты и результаты
Внедрение фреймворка мультирегионального failover позволило значительно повысить отказоустойчивость платформы и снизить риск простоев. После его внедрения было проведено несколько учений, имитирующих региональные сбои. В каждом случае платформа успешно переключалась на резервный регион без потери данных и с минимальным временем простоя.
Улучшение Business Continuity
Фреймворка мультирегионального failover значительно улучшил business continuity платформы, гарантируя ее доступность даже в случае серьезных региональных сбоев.
Уменьшение продакшн регрессий
Автоматическое переключение трафика между регионами позволило снизить количество продакшн регрессий, связанных с простоями платформы.
Улучшение SLA
Проактивный подход к обеспечению отказоустойчивости платформы позволил улучшить SLA и повысить лояльность клиентов.
Разработка и внедрение фреймворка мультирегионального failover – инвестиция в будущее вашей финтех-платформы. Хотите узнать, как мы можем помочь вам создать отказоустойчивую и надежную инфраструктуру? Посмотрите наши сервисы и свяжитесь с нами сегодня!
Связанные материалы
Детальный разбор компонентов фреймворка мультирегионального failover
Разберем подробнее ключевые компоненты фреймворка, чтобы понять, как каждый из них способствует общей отказоустойчивости системы.
Гео-распределенная база данных: Обеспечение консистентности данных
Выбор базы данных, поддерживающей синхронную репликацию, является критически важным. Необходимо учитывать следующие аспекты:
- Задержка репликации: Синхронная репликация обеспечивает консистентность данных, но может увеличить задержку при записи. Важно оценить влияние задержки на производительность платформы.
- Разрешение конфликтов: В случае возникновения конфликтов при репликации необходимо предусмотреть механизмы их автоматического или ручного разрешения.
- Мониторинг репликации: Непрерывный мониторинг процесса репликации для оперативного выявления и устранения проблем.
Пример: Использование распределенной базы данных с поддержкой multi-primary записи и автоматическим разрешением конфликтов на основе CRDT (Conflict-free Replicated Data Type).
Автоматическое переключение трафика: Балансировка нагрузки и мониторинг здоровья
Система автоматического переключения трафика должна обеспечивать быстрое и надежное перенаправление трафика в случае сбоя. Необходимо учитывать следующие факторы:
- Время переключения: Время, необходимое для обнаружения сбоя и переключения трафика, должно быть минимальным, чтобы минимизировать простой платформы.
- Критерии переключения: Критерии, определяющие необходимость переключения трафика (например, недоступность базы данных, высокая задержка сети, высокая загрузка CPU).
- Механизмы переключения: Использование DNS, балансировщиков нагрузки или других механизмов для переключения трафика.
Пример: Балансировщик нагрузки с настроенными health checks для каждого региона. При сбое в основном регионе, балансировщик автоматически перенаправляет трафик на резервный регион.
Идемпотентные транзакции: Предотвращение дублирования операций
Идемпотентность транзакций гарантирует, что повторное выполнение операции не приведет к нежелательным последствиям. Для обеспечения идемпотентности необходимо:
- Уникальные идентификаторы транзакций: Каждая транзакция должна иметь уникальный идентификатор, который используется для предотвращения дублирования.
- Проверка существования транзакции: Перед выполнением транзакции необходимо проверять, не была ли она уже выполнена.
- Логирование транзакций: Ведение журнала выполненных транзакций для аудита и восстановления данных.
Пример: Для каждого запроса генерируется UUID, который передается в заголовке. Сервис проверяет в базе данных, не был ли уже обработан запрос с таким UUID. Если был, запрос игнорируется.
Рекомендации по тестированию фреймворка
Тщательное тестирование является критически важным для обеспечения надежной работы фреймворка. Рекомендуется проводить следующие типы тестов:
- Функциональное тестирование: Проверка правильности работы всех компонентов фреймворка.
- Нагрузочное тестирование: Оценка производительности системы в условиях высокой нагрузки.
- Тестирование отказоустойчивости: Имитация различных сценариев сбоев (например, отключение электроэнергии, потеря сетевого соединения, выход из строя оборудования) и проверка корректности переключения на резервный регион.
- Регрессионное тестирование: Проверка работоспособности системы после внесения изменений в код.
- Chaos engineering: Преднамеренное внесение хаоса в систему (например, случайное отключение серверов) для проверки ее устойчивости к сбоям.
Пример внедрения фреймворка в микросервисной архитектуре
Рассмотрим пример внедрения фреймворка в финтех-платформу, построенную на микросервисной архитектуре.
- Определение критически важных сервисов: Определите сервисы, от которых зависит функционирование платформы (например, сервисы обработки платежей, авторизации, управления счетами).
- Гео-распределение сервисов: Разверните критически важные сервисы в нескольких географических регионах.
- Синхронизация данных: Используйте гео-распределенную базу данных для хранения данных, используемых критически важными сервисами. Альтернативно, можно использовать event sourcing с асинхронной репликацией событий.
- Автоматическое переключение трафика: Настройте балансировщик нагрузки или service mesh для автоматического переключения трафика между регионами в случае сбоя.
- Идемпотентность транзакций: Обеспечьте идемпотентность транзакций, выполняемых критически важными сервисами.
- Мониторинг и оповещения: Настройте систему мониторинга для наблюдения за состоянием сервисов и оповещения об инцидентах.
Углубленный пример конфигурации балансировщика нагрузки (HAProxy)
Рассмотрим более продвинутый пример конфигурации балансировщика нагрузки HAProxy:
frontend http-in
bind *:80
mode http
option http-server-close
acl healthy_region_a url_reg ^/health
use_backend region_a if healthy_region_a
default_backend region_selector
backend region_selector
mode http
server region_a_check check inter 5000 rise 2 fall 3
server region_b_check check inter 5000 rise 2 fall 3
use_backend region_a if { srv_is_up(region_a_check) }
use_backend region_b if { srv_is_up(region_b_check) }
default_backend error_page
backend region_a
mode http
server app-server-a1.example.com:8080 check inter 5000 rise 2 fall 3
server app-server-a2.example.com:8080 check inter 5000 rise 2 fall 3
backend region_b
mode http
server app-server-b1.example.com:8080 check inter 5000 rise 2 fall 3
server app-server-b2.example.com:8080 check inter 5000 rise 2 fall 3
backend error_page
mode http
errorfile 503 /etc/haproxy/errors/503.http
В этом примере:
- HAProxy прослушивает порт 80.
- `http-server-close` оптимизирует использование ресурсов.
- `region_selector` проверяет доступность регионов A и B.
- Трафик направляется в доступный регион, в противном случае отображается страница ошибки.
- Health checks настроены с интервалом 5 секунд, требуют 2 успешных проверки для подтверждения работоспособности и 3 неудачных для признания региона недоступным.
Антипаттерны в контексте безопасности
Безопасность должна быть неотъемлемой частью фреймворка мультирегионального failover. Следующие антипаттерны могут привести к серьезным уязвимостям:
- Использование небезопасных протоколов: Передача данных между регионами по незашифрованным каналам (например, HTTP вместо HTTPS).
- Совместное использование секретов: Использование одних и тех же ключей шифрования или паролей в обоих регионах. В случае компрометации одного региона, злоумышленник получит доступ и ко второму.
- Отсутствие сегментации сети: Недостаточная изоляция сети между регионами, что может позволить злоумышленнику, получившему доступ к одному региону, перемещаться по сети и атаковать другие регионы.
- Игнорирование принципа наименьших привилегий: Предоставление избыточных прав доступа пользователям и приложениям, что увеличивает риск злоупотреблений.
- Недостаточное логирование и мониторинг безопасности: Отсутствие системы обнаружения вторжений и мониторинга аномальной активности, что затрудняет своевременное обнаружение и реагирование на инциденты безопасности.
Пример: Разделение ответственности за безопасность между разными командами в разных регионах и проведение регулярных аудитов безопасности. Дополнительные сведения можно найти в статье о фреймворках доверия для Webhook-интеграций.
Заключение
Мультирегиональный failover – это сложный, но необходимый фреймворк для обеспечения непрерывности бизнеса в современных финтех-платформах. Вдумчивый подход к проектированию, внедрению и тестированию, а также учет аспектов безопасности, позволят создать отказоустойчивую и надежную инфраструктуру, способную выдерживать даже самые серьезные сбои.


