Интеграция CRM и ERP-систем критически важна для многих B2B-компаний. Однако, такие интеграции часто становятся источником операционных проблем, особенно при высоких нагрузках и частых изменениях схем данных. В этой статье мы рассмотрим, как построить operations runbook для автоматизации управления SLA в подобных интеграциях, чтобы минимизировать отток клиентов и ускорить onboarding новых инженеров. При этом, мы фокусируемся на подходах, не зависящих от конкретных вендоров CRM и ERP решений.

Фреймворк принятия решения
Прежде чем автоматизировать процессы, необходимо определить фреймворк принятия решений. В случае интеграций CRM и ERP, ключевые вопросы:
- Какие типы инцидентов наиболее критичны? (Например, сбои в синхронизации заказов, некорректное обновление статусов, проблемы с биллингом).
- Какие метрики определяют SLA? (Время решения, время отклика, процент успешных запросов).
- Какие действия необходимо предпринять при нарушении SLA? (Автоматическое уведомление, масштабирование ресурсов, переключение на резервные каналы).
Решением всех этих вопросов может стать создание графовой модели, где узлы представляют собой этапы интеграционного процесса, а ребра – зависимости и возможные точки отказа. Это позволяет визуализировать потенциальные проблемы и определить приоритеты автоматизации. Например, если графовая модель показывает, что конкретная точка интеграции (например, модуль расчета скидок) является узким местом, то фокусируемся на ее мониторинге и автоматическом масштабировании.
Пример графовой модели
Представим упрощенную графовую модель интеграции:
- CRM: Создание заказа.
- ERP: Получение заказа, проверка лимитов клиента.
- ERP: Расчет стоимости заказа.
- CRM: Обновление статуса заказа.
Каждый узел и ребро имеют ассоциированные метрики (время обработки, ошибки). Если время обработки на этапе "ERP: Расчет стоимости заказа" превышает допустимый порог, система автоматически уведомляет дежурного инженера и инициирует горизонтальное масштабирование (при необходимости).
Risk appetite
Определение допустимого уровня риска (risk appetite) – следующий важный шаг. Необходимо установить:
- Какой процент ошибок является приемлемым?
- Какое максимальное время простоя допустимо?
- Какие типы данных требуют особого внимания с точки зрения безопасности и целостности?
Risk appetite напрямую влияет на стратегию автоматизации. Если компания не готова к высоким рискам, необходимы более консервативные подходы с активным мониторингом и минимальной автоматизацией. При более высоком уровне толерантности к риску можно использовать более агрессивные стратегии автоматизации с автоматическим переключением на резервные системы и самовосстановлением.
Geo-пороги
Для компаний с географически распределенной инфраструктурой важно учитывать geo-пороги. Разместите компоненты интеграции в нескольких регионах и настройте автоматическое переключение между ними в случае сбоев.
- Мониторинг задержек между регионами.
- Автоматическое переключение трафика в регион с меньшей задержкой.
- Использование GeoDNS для оптимальной маршрутизации пользователей.
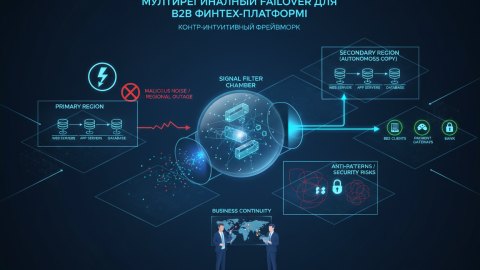
Подробнее про мультирегиональный failover и B2B финтех-платформы можно прочитать в нашей статье.
Эскалация
Не все проблемы можно решить автоматически. Необходимо определить четкие правила эскалации инцидентов, включая:
- Уровни эскалации: Первая линия поддержки, дежурный инженер, команда разработки, руководство.
- Каналы связи: Email, SMS, мессенджеры, телефон.
- Критерии эскалации: Время, тип инцидента, влияние на бизнес.
Автоматизируйте процесс эскалации, чтобы уведомления отправлялись автоматически в нужные каналы и ответственным лицам. Каждый шаг эскалации должен быть четко документирован и отслеживаться.
Пример эскалации
Если автоматическая система не смогла решить проблему с синхронизацией данных (например, из-за невалидных данных CRM), сначала уведомляется дежурный инженер. Если проблема не решена в течение 15 минут, уведомляется команда разработки. Если влияние на бизнес критично (например, остановлены продажи), уведомляется руководство и запускается процесс ручного восстановления данных.
Governance
Для поддержания стабильности и эффективности автоматизации критически важен governance. Он включает:
- Регулярный аудит системы автоматизации.
- Анализ эффективности автоматизации.
- Обновление правил автоматизации в соответствии с изменениями бизнеса.
- Обучение персонала.
Governance должен быть интегрирован в общую систему управления IT-инфраструктурой компании. Особое внимание следует уделять:
- Версионированию правил автоматизации.
- Тестированию изменений перед внедрением в production.
- Документированию всех изменений в системе.
Автоматизированные пайплайны можно использовать для создания отчетов о состоянии SLA, эффективности автоматизации, и динамике ключевых метрик. Смотрите больше деталей в статье про Automated Reporting Pipelines для B2B.
Заключение
Автоматизация management B2B-интеграций CRM и ERP – это сложная, но важная задача. С помощью правильно спроектированного operations runbook, графовой модели, четких правил эскалации и governance можно значительно повысить стабильность системы, снизить издержки на поддержку и ускорить onboarding новых инженеров. Все это приводит к повышению удовлетворенности клиентов и росту бизнеса.
Хотите построить надёжную и масштабируемую архитектуру для вашей B2B SaaS платформы? Свяжитесь с нами, чтобы обсудить ваши задачи и найти оптимальное решение.