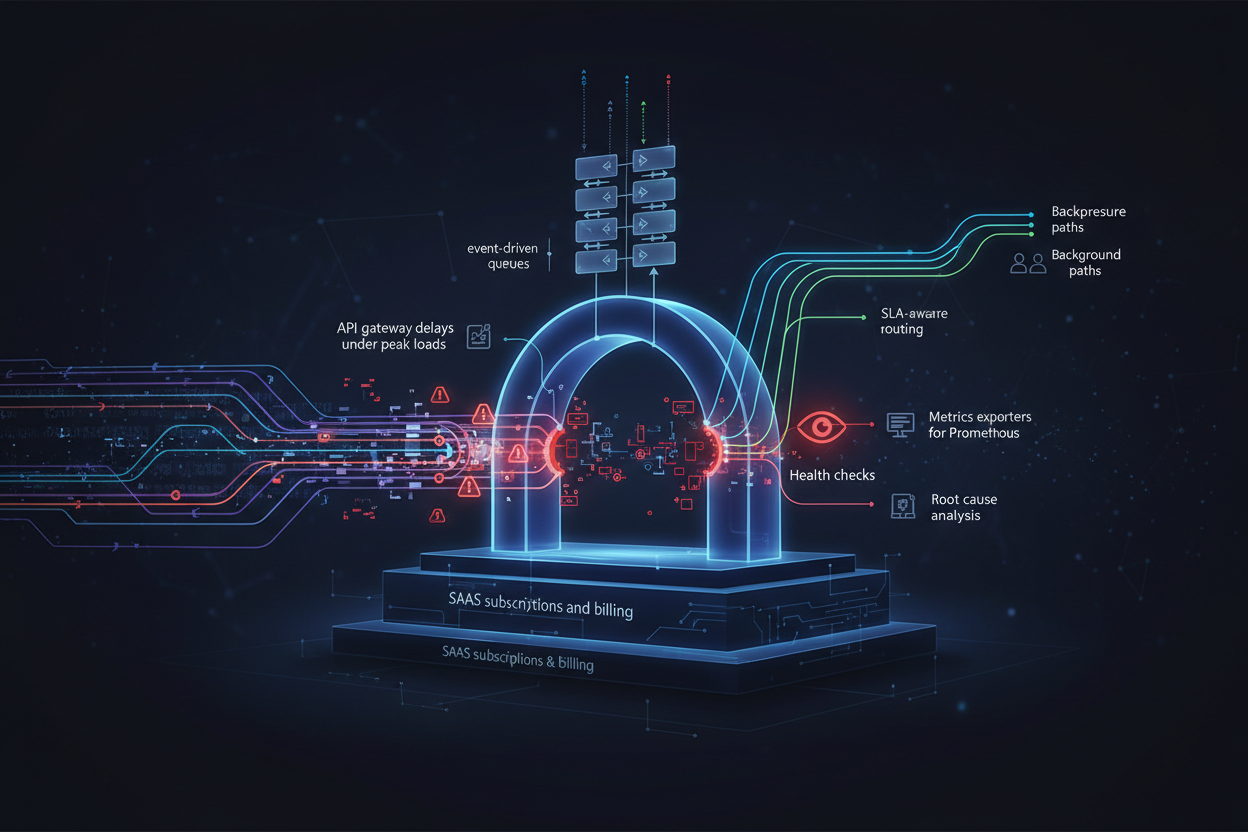
Настройка операционной модели начинается с симуляции атак и пиковых нагрузок на API-шлюз. Используя сценарии, приближённые к реальному пиковому трафику партнёрской сети, выявляются узкие места в маршрутизации запросов, очередях и балансировке. Ключевые сигналы детекта включают увеличение latency, таймауты подписок и ошибки биллинга.
Сигналы и метрики наблюдаемости
- Измерения percentile latency (95/99): стабильно ли время отклика?
- Rate of timeout вызовов на critical путях подписок и биллинга.
- Error rate из-за resource throttling (CPU, Memory, DB connections).
- Correlation log-шагов с SLA-событиями из партнёрской сети.
Контрмеры: архитектурные trade-offs и операционные практики
Для устранения задержек применяются многопоточные event-driven очереди и оптимизированные API Gateway с разделением критичных и фоновый запросов. Важным элементом становится использование SLA-aware routing и backpressure-механизмов на границах системы.
Пример кода: backpressure middleware для Node.js API Gateway
function backpressureMiddleware(req, res, next) {
if (isSystemOverloaded()) {
return res.status(429).json({ error: 'System is overloaded, please retry later' });
}
next();
}
Внедрение системных health checks и metrics exporter для Prometheus позволяет быстро детектировать отклонения в нагрузке и вовремя масштабировать API-шлюзы.
Уроки и антипаттерны: что стоит избегать
- Монолитное построение API Gateway без event-driven разделения приводит к 100% деградации при пиковых нагрузках.
- Отсутствие SLA-driven routing увеличивает latency на критичных запросах, сказываясь на retention.
- Игнорирование backpressure и отказоустойчивых очередей создаёт cascade failures и обрушивает партнёрскую сеть.
Заключение и call to action
Комплексное внедрение операционной модели с акцентом на SLA, observability и event-driven подход позволяет значительно снизить задержки API-шлюзов под нагрузкой и повысить retention. Для консультации и внедрения современных практик автоматизации партнёрской сети обращайтесь в нашу команду на /services/.
Рекомендованные конкуренты и ресурсы для углубления
- Сервисы мониторинга и load testing: Grafana Labs, K6.io
- AI-инструменты для анализ логов и инцидентов: Sumo Logic, Datadog AI
- Mindmap платформа для архитекторов: Miro с интеграцией EventStorming
Внутренние ссылки
- Product Strategy and Architecture Workshops: Root Cause Analysis для уверенных релизов B2B SaaS
- Event-Driven Platform Design: чеклист production readiness для observability и service-level ретеншена
SaaS API Operating Model: устранение задержек API-шлюза при пиковых нагрузках для retention-механик
В современном SaaS с подписками и биллингом высокая нагрузка на API-шлюзы становится узким местом, влияющим на retention. В статье рассматриваем операционную модель партнёрской сети с методами выявления и устранения задержек API при пиковых нагрузках для повышения повторных продаж и операционной прозрачности.
Red Team взгляд: выявление root cause задержек API-шлюза
Настройка операционной модели начинается с симуляции атак и пиковых нагрузок на API-шлюз. Используя сценарии, приближённые к реальному пиковому трафику партнёрской сети, выявляются узкие места в маршрутизации запросов, очередях и балансировке. Ключевые сигналы детекта включают увеличение latency, таймауты подписок и ошибки биллинга.
Сигналы и метрики наблюдаемости
- Измерения percentile latency (95/99): стабильно ли время отклика?
- Rate of timeout вызовов на critical путях подписок и биллинга.
- Error rate из-за resource throttling (CPU, Memory, DB connections).
- Correlation log-шагов с SLA-событиями из партнёрской сети.
Контрмеры: архитектурные trade-offs и операционные практики
Для устранения задержек применяются многопоточные event-driven очереди и оптимизированные API Gateway с разделением критичных и фоновых запросов. Важным элементом становится использование SLA-aware routing и backpressure-механизмов на границах системы.
Пример кода: backpressure middleware для Node.js API Gateway
function backpressureMiddleware(req, res, next) {
if (isSystemOverloaded()) {
return res.status(429).json({ error: 'System is overloaded, please retry later' });
}
next();
}
Внедрение системных health checks и metrics exporter для Prometheus позволяет быстро детектировать отклонения в нагрузке и вовремя масштабировать API-шлюзы.
Уроки и антипаттерны: что стоит избегать
- Монолитное построение API Gateway без event-driven разделения приводит к 100% деградации при пиковых нагрузках.
- Отсутствие SLA-driven routing увеличивает latency на критичных запросах, сказываясь на retention.
- Игнорирование backpressure и отказоустойчивых очередей создаёт cascade failures и обрушивает партнёрскую сеть.
Заключение и call to action
Комплексное внедрение операционной модели с акцентом на SLA, observability и event-driven подход позволяет значительно снизить задержки API-шлюзов под нагрузкой и повысить retention. Для консультации и внедрения современных практик автоматизации партнёрской сети обращайтесь в нашу команду на /services/.
Рекомендованные конкуренты и ресурсы для углубления
- Сервисы мониторинга и load testing: Grafana Labs, K6.io
- AI-инструменты для анализ логов и инцидентов: Sumo Logic, Datadog AI
- Mindmap платформа для архитекторов: Miro с интеграцией EventStorming
Внутренние ссылки
- Product Strategy and Architecture Workshops: Root Cause Analysis для уверенных релизов B2B SaaS
- Event-Driven Platform Design: чеклист production readiness для observability и service-level ретеншена

