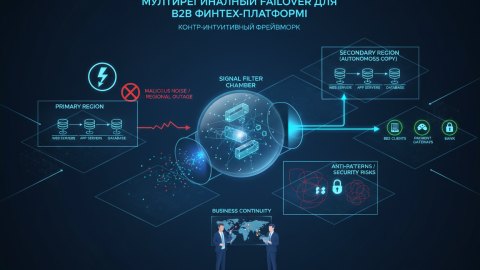
В мире микросервисной архитектуры отказоустойчивость – это не просто модное слово, а насущная необходимость. Но как её достичь на практике, особенно когда на кону стоит пользовательский опыт и бизнес-репутация? Я убежден, что ключ к успеху – это взгляд на отказоустойчивость через призму Reliability Engineering и понимание пути пользователя. Разберем основные этапы.
Путь пользователя: от доверия к действию
Первый шаг – это осознание, как пользователь взаимодействует с вашей системой. Каждый клик, каждое действие – это потенциальная точка отказа. Начинать нужно с доверия (trust).
Trust-сигналы: проверка на входе
Пользователь должен чувствовать себя в безопасности с самого начала. Trust-сигналы – это индикаторы, которые подтверждают легитимность и надежность системы. Что может пригодиться:
* SSL сертификаты
* Четкая политика конфиденциальности и условия использования
* Информация о компании и контакты
* Отзывы других пользователей
Мини-кейс: Однажды, работая с B2B SaaS платформой, я заметил, что пользователи часто отваливаются на этапе регистрации. Анализ показал, что отсутствие четкой информации о политике обработки данных вызывало недоверие. После добавления развернутого описания, конверсия в регистрацию выросла на 15%.
Risk-gates: фильтруем нежелательный трафик
Следующий этап – это установка барьеров для предотвращения нежелательных действий. Risk-gates – это механизмы, которые анализируют входящий трафик и блокируют подозрительные запросы:
* Rate limiting: ограничение количества запросов с одного IP адреса.
* CAPTCHA: защита от ботов.
* WAF (Web Application Firewall): фильтрация вредоносного трафика.
* IP Intelligence: анализ репутации IP адресов (см.
Проактивная Архитектура Безопасности: От IP Intelligence к ROI).
Backend-логика: сердце отказоустойчивости
Когда пользователь прошел через risk-gates, начинается работа backend-логики. Здесь критически важно обеспечить надежность и предсказуемость.
Транзакции и Идемпотентность
Обеспечьте атомарность операций. Если операция состоит из нескольких шагов, используйте транзакции, чтобы либо выполнить все шаги, либо откатить изменения. В контексте микросервисов это может быть сложно, но необходимо. Для сложных транзакционных потоков изучите
Идемпотентность в B2B SaaS: Playbook архитектора для транзакционных потоков.
Резервирование и Репликация
Никогда не полагайтесь на единственный экземпляр сервиса. Резервируйте ресурсы и реплицируйте данные. Используйте несколько копий сервисов, распределенных по разным зонам доступности. Данные должны быть реплицированы в несколько дата-центров.
Circuit Breaker
Этот паттерн позволяет предотвратить каскадные сбои. Если сервис начинает выдавать ошибки, circuit breaker автоматически прерывает запросы к нему, давая ему время на восстановление.
Retry Policies
Временные сбои – неизбежность. Используйте retry policies, чтобы автоматически повторять неудачные запросы. Важно настроить backoff, чтобы не перегружать систему.
Дашборды: визуализация проблем
Наблюдаемость – это ключ к пониманию состояния системы. Дашборды должны предоставлять информацию о ключевых метриках:
* Error rate
* Latency
* Throughput
* Resource utilization
Используйте алерты, чтобы оперативно реагировать на проблемы.
Рекомендации: чек-лист отказоустойчивости
* **Определите критические пути пользователя:** Какие функции наиболее важны для вашего бизнеса?
* **Внедрите trust-сигналы:** Укрепите доверие пользователей к вашей системе.
* **Используйте risk-gates:** Защитите систему от нежелательного трафика.
* **Обеспечьте надежность backend-логики:** Используйте транзакции, резервирование, circuit breaker и retry policies.
* **Визуализируйте проблемы с помощью дашбордов:** Наблюдайте за ключевыми метриками и оперативно реагируйте на алерты.
В заключение, отказоустойчивость – это не разовое мероприятие, а непрерывный процесс. Постоянно анализируйте свою систему, выявляйте слабые места и улучшайте ее. А для более глубокой интеграции архитектурных решений в ваш бизнес, посмотрите на наши
сервисы. Надеюсь, этот подход поможет сделать вашу систему надежной и устойчивой к любым вызовам. Посмотрите также как Event-Driven подходы помогают в масштабируемости - /blog/obshchiy/event-driven-platformy-dannykh-razveivaem-hajp-fokusiruemsya-na-roi/.
Связанные материалы