В динамичном мире B2B, где каждое взаимодействие имеет значение, надежность и производительность становятся критическими факторами успеха. Наблюдаемость – это не просто модное слово, а фундаментальная необходимость для достижения операционной зрелости. В этом decision memo я рассмотрю, как правильно подобранные метрики наблюдаемости влияют на способность вашей организации быстро реагировать на инциденты, оптимизировать производительность и обеспечивать высокий уровень обслуживания для ваших клиентов.
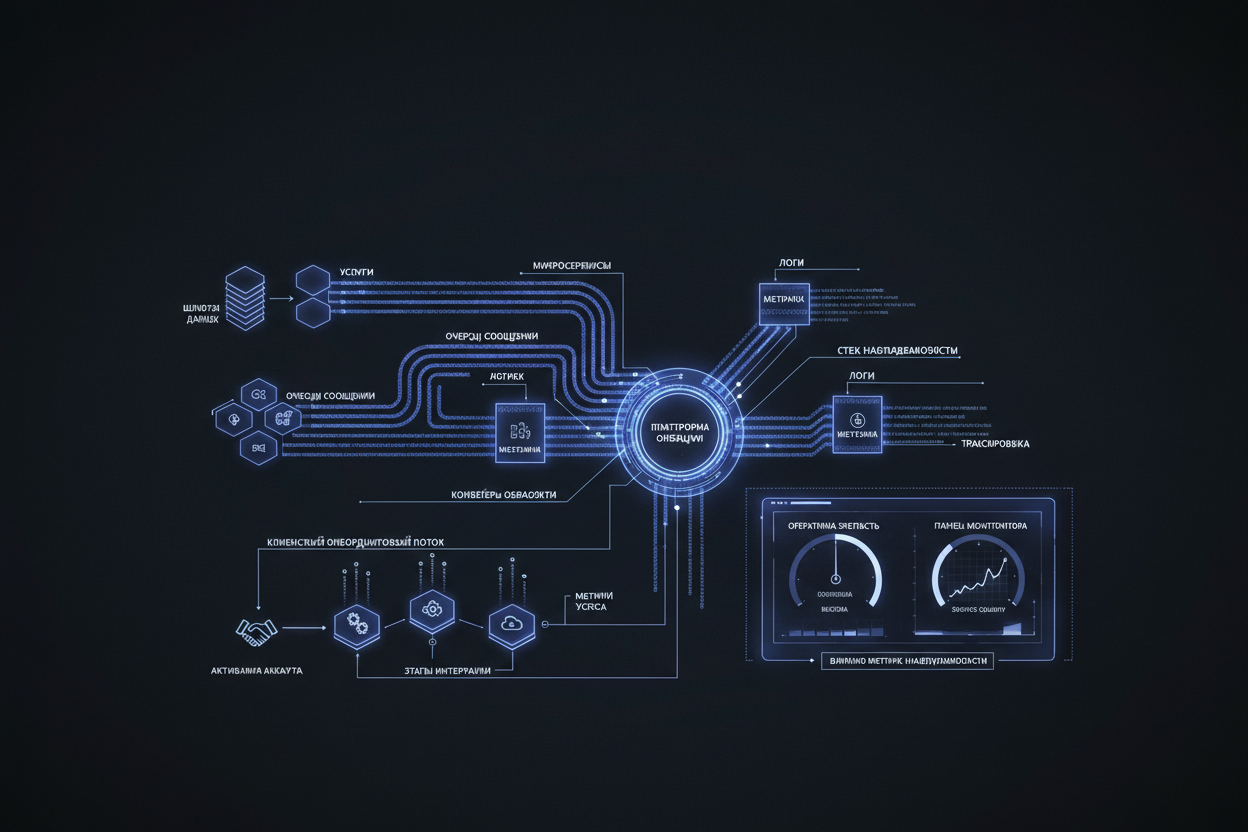
Расширенный FAQ: Ответы на Ключевые Вопросы
Что такое операционная зрелость и почему она важна для B2B?
Операционная зрелость – это уровень развития процессов, технологий и навыков, позволяющих организации эффективно и надежно предоставлять свои услуги. В B2B контексте, зрелость напрямую влияет на удовлетворенность клиентов, удержание и рост бизнеса. Высокий уровень зрелости означает предсказуемые результаты, минимальные простои и быструю адаптацию к изменениям.
Какие метрики наблюдаемости наиболее важны для B2B-систем?
Спектр метрик широк, но я рекомендую сосредоточиться на следующих ключевых категориях:
- Производительность: Задержка (latency), пропускная способность (throughput), использование ресурсов (CPU, память, диск).
- Ошибки: Количество ошибок (error rate), типы ошибок (5xx, 4xx), частота повторных попыток (retry rate).
- Насыщенность: Уровень загрузки ресурсов, время ожидания в очередях, количество активных соединений.
- Использование: Количество активных пользователей, частота использования функций, объемы передаваемых данных.
Как выбрать правильные инструменты для сбора и анализа метрик?
Выбор инструментов зависит от вашей инфраструктуры, бюджета и потребностей. Важно учитывать следующие факторы:
- Масштабируемость: Способность обрабатывать большие объемы данных.
- Интеграция: Совместимость с существующими системами и инструментами.
- Визуализация: Возможность создания понятных и информативных дашбордов.
- Алертинг: Настройка оповещений о критических событиях.
- Стоимость: Общая стоимость владения, включая лицензии, инфраструктуру и поддержку.
Как определить целевые значения для метрик и что делать, если они нарушаются?
Определение целевых значений – это итеративный процесс, требующий понимания вашей системы и бизнес-требований. Начните с базовых значений, основанных на исторических данных и лучших практиках, затем постепенно оптимизируйте их на основе опыта и обратной связи. При нарушении целевых значений необходимо оперативно выявлять причину, предпринимать корректирующие действия и анализировать результаты, чтобы предотвратить повторение подобных ситуаций в будущем.
Подробные Ответы: Углубляемся в Детали
Практические примеры метрик и их интерпретация
Рассмотрим несколько примеров:
- Задержка API: Если задержка ответа API превышает 200 мс, это может указывать на проблемы с производительностью базы данных, сетевыми задержками или неэффективным кодом.
- Error Rate при обработке заказов: Если процент ошибок при обработке заказов превышает 1%, необходимо проверить интеграцию с платежными системами, логику обработки транзакций и наличие ошибок в коде.
- Использование CPU на серверах: Если использование CPU на серверах превышает 80% в течение длительного времени, это может указывать на необходимость масштабирования инфраструктуры, оптимизации кода или наличия утечек памяти.
Шаги по внедрению наблюдаемости
- Определите цели: Что вы хотите измерить и почему? Какие бизнес-показатели вы хотите улучшить?
- Выберите метрики: Определите ключевые метрики, которые отражают состояние вашей системы и влияют на ваши цели.
- Внедрите инструменты: Выберите и настройте инструменты для сбора, хранения и анализа метрик.
- Создайте дашборды: Разработайте дашборды, которые визуализируют метрики и позволяют быстро выявлять проблемы.
- Настройте алерты: Установите пороговые значения для метрик и настройте оповещения о критических событиях.
- Автоматизируйте реагирование: Интегрируйте систему мониторинга с инструментами автоматизации для автоматического устранения проблем.
- Анализируйте и улучшайте: Регулярно анализируйте данные, определяйте узкие места и принимайте меры по оптимизации производительности и надежности.
Как обеспечить соответствие требованиям безопасности и конфиденциальности при сборе метрик?
Безопасность и конфиденциальность данных – это приоритет. Убедитесь, что вы соблюдаете следующие правила:
- Шифруйте данные: Используйте шифрование для защиты метрик при передаче и хранении.
- Анонимизируйте данные: Удаляйте или маскируйте персональные данные из метрик.
- Контролируйте доступ: Ограничивайте доступ к метрикам только авторизованным пользователям.
- Соблюдайте политики: Убедитесь, что ваши методы сбора и обработки метрик соответствуют политикам безопасности и конфиденциальности вашей организации.
Реальные Конфиги: Пример Практической Реализации
Мини-кейс: Оптимизация производительности API обработки платежей
В одной из B2B SaaS компаний наблюдались проблемы с производительностью API обработки платежей. Клиенты жаловались на задержки и ошибки при оплате счетов. Для решения проблемы была внедрена система наблюдаемости, включающая сбор метрик задержки, error rate и использования ресурсов. Анализ данных показал, что основной причиной задержек является неоптимизированный запрос к базе данных. После оптимизации запроса задержка уменьшилась на 50%, а процент ошибок снизился до нуля. В результате улучшилась удовлетворенность клиентов и увеличилась конверсия.
Пример YAML-конфигурации для сбора метрик Prometheus
scrape_configs:
- job_name: 'api_payments'
metrics_path: '/metrics'
static_configs:
- targets: ['api-payments.example.com:8080']
relabel_configs:
- source_labels: [__address__]
target_label: instance
- source_labels: [__name__]
target_label: metric
Этот пример показывает базовую конфигурацию Prometheus для сбора метрик с API обработки платежей. Необходимо кастомизировать его под ваши нужды.
Edge-Cases: Неочевидные Ситуации и Решения
Влияние внешних зависимостей на наблюдаемость
Когда ваша система зависит от внешних сервисов (сторонние API, облачные платформы), необходимо учитывать их влияние на наблюдаемость. Важно отслеживать доступность, задержку и ошибки внешних сервисов, чтобы быстро выявлять проблемы, связанные с ними. Можно использовать инструменты мониторинга внешних сервисов, такие как health checks и synthetic monitoring. Подробнее про отказоустойчивость можно узнать здесь.
Как избежать перегрузки системы мониторинга
Система мониторинга, которая собирает слишком много данных, может сама стать причиной проблем с производительностью. Важно тщательно выбирать метрики, собирать только необходимую информацию и использовать агрегацию и сэмплирование для уменьшения объема данных. Подумайте об адаптивном управлении рисками, как описано в этой статье.
Антипаттерны в мониторинге
- Игнорирование алертов: Если алерты игнорируются, они теряют свою ценность. Необходимо оперативно реагировать на алерты и устранять причины их возникновения.
- Слишком много алертов: Слишком большое количество алертов может привести к информационной перегрузке и снижению внимания к действительно важным событиям. Важно правильно настроить пороговые значения и приоритеты для алертов.
- Отсутствие контекста: Метрики без контекста трудно интерпретировать. Необходимо добавлять контекст к метрикам, например, информацию о версии приложения, окружении и бизнес-процессах.
Вывод: Инвестируйте в зрячесть
Наблюдаемость – это не просто техническая задача, а стратегическая инвестиция в операционную зрелость и успех вашего B2B бизнеса. Правильно подобранные метрики, эффективные инструменты и отлаженные процессы позволяют быстро реагировать на инциденты, оптимизировать производительность и обеспечивать высокий уровень обслуживания для ваших клиентов. Помните, что наблюдаемость требует постоянного внимания и улучшения. Регулярно анализируйте данные, определяйте узкие места и принимайте меры по оптимизации.
Если вам нужна профессиональная помощь в построении архитектуры, обеспечивающей наблюдаемость и зрелость системы, обращайтесь за консультацией: узнать больше об услугах.
Связанные материалы
Продвинутые сценарии наблюдаемости
Наблюдаемость и A/B-тестирование
Наблюдаемость становится критически важной при проведении A/B-тестов. Сбор метрик позволяет оценить влияние изменений не только на ключевые бизнес-показатели (конверсию, удержание), но и на производительность системы (задержку, использование ресурсов). Это помогает принимать обоснованные решения о внедрении новых функций и оптимизации существующих.
Пример: Проводя A/B-тест новой версии страницы оформления заказа, я не только отслеживаю конверсию, но и метрики задержки API платежей. Если новая версия страницы значительно увеличивает задержку, даже при небольшом росте конверсии, я отдаю предпочтение более производительной версии.
Чеклист: Наблюдаемость для A/B-тестирования
- Определите ключевые метрики производительности, которые могут быть затронуты A/B-тестом (задержка API, использование CPU, количество ошибок).
- Настройте сбор этих метрик для каждой группы A/B-теста (контрольной и тестовой).
- Визуализируйте метрики на дашбордах, чтобы быстро выявлять различия между группами.
- Установите пороги для метрик производительности и настройте оповещения о критических отклонениях.
- Анализируйте данные и принимайте решения на основе комплексной оценки бизнес-показателей и метрик производительности.
Наблюдаемость и Feature Flags
Feature flags позволяют включать и выключать функциональность в реальном времени без развертывания нового кода. Наблюдаемость играет важную роль в управлении feature flags, позволяя оценить влияние новых функций на систему и на пользователей. Мониторинг позволяет оперативно реагировать на проблемы, связанные с включением новых функций, и быстро откатывать изменения.
Пример: Внедряя новую систему рекомендаций товаров, я использую feature flag для постепенного включения функциональности для пользователей. С помощью мониторинга я отслеживаю влияние системы рекомендаций на конверсию, средний чек и задержку API. Если возникает проблема с производительностью, я могу быстро отключить feature flag и вернуться к предыдущей версии.
Антипаттерн: Слепое включение feature flags без мониторинга
Включать feature flags без сбора метрик – это как ехать с завязанными глазами. Вы не знаете, как новые функции влияют на вашу систему и на пользователей. Это может привести к серьезным проблемам с производительностью, безопасности и пользовательским опытом.
Наблюдаемость и CI/CD
Интеграция системы наблюдаемости в конвейер CI/CD позволяет автоматизировать оценку качества новых билдов и выявлять проблемы на ранних этапах разработки. Можно настроить автоматические проверки метрик производительности и безопасности после каждого развертывания и блокировать выпуск билдов, если они не соответствуют заданным критериям.
Шаги по интеграции наблюдаемости в CI/CD
- Определите ключевые метрики качества, которые необходимо проверять после каждого развертывания (время ответа API, количество ошибок, использование ресурсов).
- Настройте автоматический сбор этих метрик после развертывания нового билда.
- Создайте скрипты, которые проверяют значения метрик и сравнивают их с заданными пороговыми значениями.
- Интегрируйте эти скрипты в конвейер CI/CD и настройте автоматическую блокировку выпуска билдов, если они не соответствуют критериям качества.
Построение культуры наблюдаемости
Наблюдаемость – это не только техническая задача, но и культурная. Важно построить в организации культуру, в которой каждый член команды понимает важность наблюдаемости и активно использует ее для решения проблем и улучшения системы. Я считаю, что такая культура способствует большей ответственности и более осознанным решениям.
Вовлечение команды
Для построения культуры наблюдаемости необходимо вовлекать в процесс всех членов команды: разработчиков, тестировщиков, DevOps-инженеров, менеджеров. Каждый должен понимать, как работает система мониторинга, как собираются метрики и как их можно использовать для решения своих задач. Регулярные тренинги и семинары помогут команде освоить инструменты и методы наблюдаемости.
Обмен знаниями
Важно создать в организации систему обмена знаниями о наблюдаемости. Разработчики должны делиться опытом по настройке мониторинга для своих приложений, DevOps-инженеры – по автоматизации реагирования на инциденты, менеджеры – по использованию метрик для принятия бизнес-решений. Я, например, активно использую внутренние блоги и вики для обмена опытом.
Ответственность за метрики
Каждый член команды должен нести ответственность за определенные метрики, которые отражают состояние его области ответственности. Разработчик отвечает за производительность своего кода, DevOps-инженер – за доступность инфраструктуры, менеджер – за удовлетворенность клиентов. Важно, чтобы каждый понимал, как его работа влияет на эти метрики и что он может сделать для их улучшения.
Заключение
В заключение, хочу подчеркнуть, что наблюдаемость – это непрерывный процесс, который требует постоянного внимания и улучшения. Правильно подобранные метрики, эффективные инструменты и отлаженные процессы позволяют не только быстро реагировать на инциденты, но и прогнозировать их возникновение, оптимизировать производительность системы и обеспечивать высокий уровень обслуживания для ваших клиентов. Инвестируйте в наблюдаемость и вы увидите, как это положительно скажется на вашем B2B бизнесе.