В мире SaaS-платформ, особенно в B2B-сегменте, интеграция с партнерскими системами и внешними API становится краеугольным камнем. Например, представим e-commerce платформу, интегрированную с несколькими платежными шлюзами. Сбои в сверке платежей между этими системами могут привести к серьезным финансовым потерям, недовольству клиентов и нарушению SLA. Наша цель – создать надежный и масштабируемый API-шлюз, который обеспечивает сверку статусов платежей между различными системами, минимизируя риски и обеспечивая соблюдение жестких сроков управленческой отчетности.
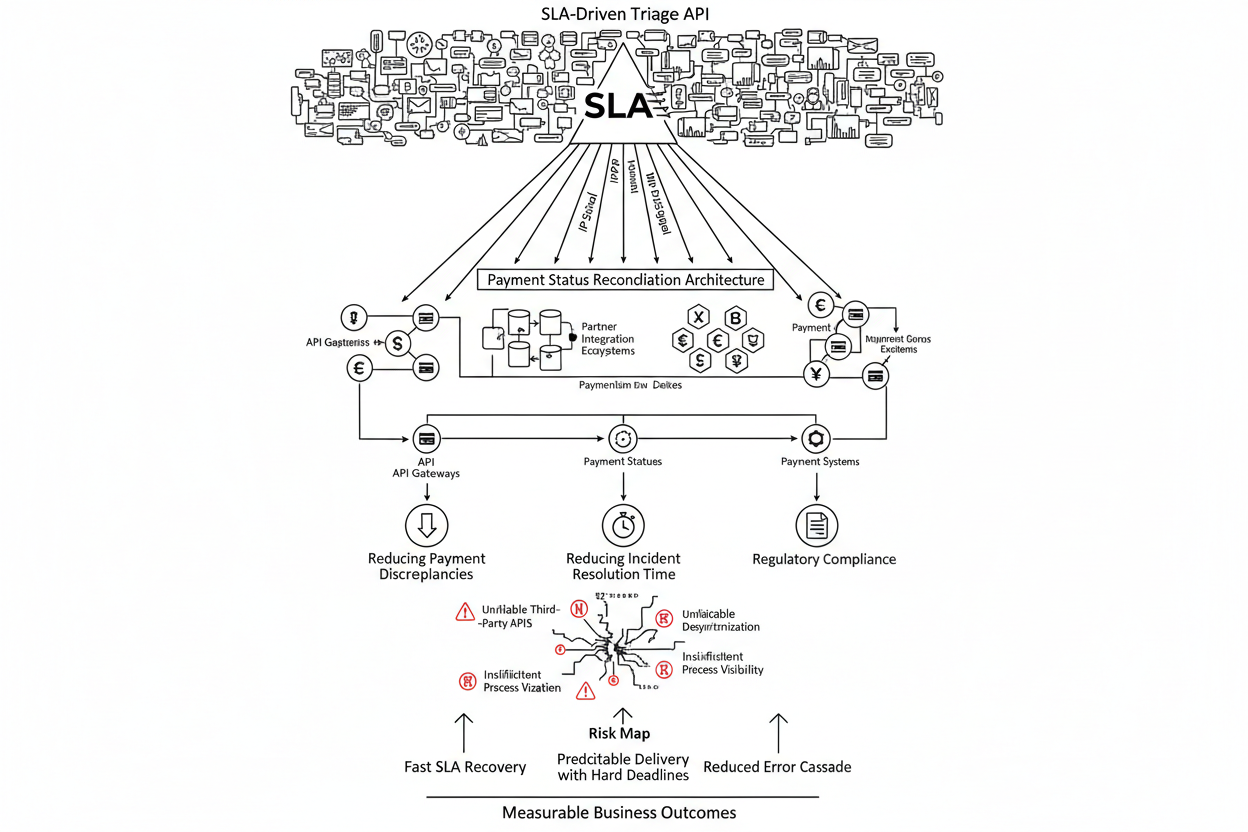
Контрольные цели сверки статусов платежей
Чтобы избежать хаоса и обеспечить четкость, определите цели, которых вы хотите достичь с помощью архитектуры сверки платежей. Эти цели должны быть измеримыми и достижимыми. Вот несколько примеров:
- Снижение количества расхождений в платежах на X% в квартал. Это прямо влияет на финансовую точность и уменьшает необходимость в ручной обработке.
- Сокращение времени разрешения инцидентов, связанных с платежами, на Y%. Это улучшает клиентский опыт и снижает операционные издержки.
- Обеспечение соответствия требованиям регуляторов в сфере финансовых операций. Это критически важно для поддержания доверия и избежания штрафов.
Карта рисков: Где может пойти что-то не так?
Прежде чем внедрять какие-либо изменения, важно понимать потенциальные риски. Рассмотрим несколько распространенных проблем, возникающих при сверке статусов платежей:
- Ненадежные API сторонних сервисов. Внешние API могут быть недоступны или возвращать некорректные данные, что приводит к расхождениям.
- Рассинхронизация данных между системами. Различные базы данных могут обновляться с разной скоростью, что создает временные несоответствия.
- Недостаточная видимость процессов сверки. Отсутствие мониторинга и логирования затрудняет выявление и устранение проблем.
- Ошибки при обработке edge-cases. Например, возвраты платежей, частичные оплаты или транзакции с ошибками требуют специальной обработки.
Как только вы определили риски, можно разработать план по их смягчению. Это включает в себя внедрение надежных механизмов обработки ошибок, мониторинг и оповещения, а также четкие процедуры эскалации.
Техпроверка: Архитектурные решения для надежной сверки
Теперь перейдем к техническим деталям. Какими архитектурными решениями можно гарантировать надежную сверку статусов платежей?
1. Event-Driven Архитектура
Вместо периодических запросов к различным системам, можно использовать подход, основанный на событиях. Каждое изменение статуса платежа (например, создание, успешное завершение, отмена) генерирует событие, которое обрабатывается заинтересованными системами. Это позволяет поддерживать данные в актуальном состоянии почти в реальном времени.
# Пример публикации события об изменении статуса платежа
import redis
import json
redis_client = redis.Redis(host='localhost', port=6379, db=0)
def publish_payment_event(payment_id, status):
event_data = {
'payment_id': payment_id,
'status': status
}
redis_client.publish('payment_events', json.dumps(event_data))
publish_payment_event('12345', 'success')
2. Идемпотентные операции
При работе с распределенными системами всегда есть риск, что сообщение (событие) будет обработано несколько раз. Чтобы избежать дублирования данных и некорректных операций, необходимо обеспечить идемпотентность критически важных операций. Это означает, что повторное выполнение операции должно приводить к тому же результату, что и однократное.
Подробнее об идемпотентности в B2B SaaS можно почитать в нашей статье Идемпотентность в B2B SaaS: Playbook архитектора для транзакционных потоков.
3. Dead Letter Queue (DLQ)
Неизбежно возникают ситуации, когда обработка события завершается с ошибкой. Чтобы такие события не терялись и не блокировали всю систему, их следует помещать в Dead Letter Queue. Это специальная очередь, где хранятся события, которые не удалось обработать с первой попытки. Анализ содержимого DLQ позволяет выявлять проблемные места и улучшать систему.
# Пример обработки события из DLQ
try:
process_payment(payment_id)
except Exception as e:
# Log the error and move the message to the DLQ
logger.error(f"Failed to process payment {payment_id}: {e}")
redis_client.rpush('payment_dlq', json.dumps(event_data))
4. Мониторинг и оповещения
Невозможно обеспечить надежность системы без надлежащего мониторинга. Необходимо отслеживать ключевые метрики, такие как количество обработанных событий, время обработки, количество ошибок и размер DLQ. При обнаружении аномалий следует немедленно отправлять оповещения ответственным командам.
5. API Gateway с Policy-Driven Маршрутизацией
Для управления доступом и маршрутизацией запросов к различным API-сервисам, целесообразно использовать API Gateway. Он позволяет централизованно применять политики безопасности, аутентификации и авторизации. Policy-driven маршрутизация позволяет динамически изменять маршруты запросов в зависимости от различных факторов, таких как нагрузка на сервисы или статус платежного шлюза. Это особенно важно в контексте партнерских интеграций, где требования к безопасности и доступности могут быть разными. Читайте подробнее в статье Сквозная наблюдаемость API и lineage tracking для SLA: playbook и AI-ассистент для developer portal.
6. Retry-механизмы с экспоненциальной задержкой
Временные сбои в работе API – обычное явление. Вместо того, чтобы сразу же отправлять событие в DLQ, следует попытаться обработать его повторно. При этом важно использовать экспоненциальную задержку между попытками, чтобы не перегружать систему.
# Пример retry-механизма с экспоненциальной задержкой
import time
def retry_with_backoff(func, args=(), max_retries=5, base_delay=1):
for attempt in range(max_retries):
try:
return func(*args)
except Exception as e:
delay = base_delay * (2 ** attempt)
print(f"Attempt {attempt + 1} failed, retrying in {delay} seconds...")
time.sleep(delay)
print("Max retries reached, giving up.")
# Пример использования
def call_payment_api(payment_id):
# Simulate an API call that might fail
if random.random() < 0.5:
raise Exception("API call failed")
return "Payment processed successfully"
retry_with_backoff(call_payment_api, args=('12345',))
Отчетность: Триаж инцидентов и метрики
Регулярная отчетность необходима для оценки эффективности архитектуры сверки платежей. Следует отслеживать ключевые метрики, такие как:
- Количество расхождений в платежах.
- Время разрешения инцидентов.
- Количество событий в DLQ.
- Время обработки событий.
- Процент успешных повторных попыток.
На основе этих данных можно выявлять проблемные места и принимать меры по улучшению системы. Эффективно выстроенная система триажа позволит быстро определять приоритетность инцидентов и направлять их соответствующим командам для решения.
Результат: SLA и снижение каскада ошибок
Внедрение описанных выше архитектурных решений позволяет значительно повысить надежность и предсказуемость сверки статусов платежей. Это приводит к следующим результатам:
- Сокращение финансовых потерь. Уменьшение количества расхождений в платежах напрямую влияет на прибыль компании.
- Повышение удовлетворенности клиентов. Более быстрое и точное разрешение проблем с платежами улучшает клиентский опыт.
- Соблюдение требований регуляторов. Обеспечение соответствия требованиям в сфере финансовых операций позволяет избежать штрафов и поддерживать доверие.
- Снижение операционных издержек. Автоматизация процессов сверки и триажа уменьшает необходимость в ручной обработке и снижает нагрузку на службу поддержки.
В заключение, надежная архитектура сверки статусов платежей является критически важным компонентом любой SaaS-платформы, особенно в B2B-сегменте. Внедрение event-driven подхода, идемпотентных операций, DLQ, мониторинга и retry-механизмов позволяет значительно повысить надежность, предсказуемость и масштабируемость системы. Не упустите возможность оптимизировать свою архитектуру и обеспечить бесперебойную работу ваших интеграций – свяжитесь с нами для консультации.
Связанные материалы
Расширенные стратегии оптимизации сверки статусов платежей
В предыдущих разделах мы рассмотрели ключевые компоненты надежной архитектуры сверки статусов платежей. Однако, чтобы добиться максимальной эффективности и устойчивости системы, необходимо учитывать и другие аспекты. Рассмотрим несколько расширенных стратегий, которые помогут оптимизировать процесс сверки и уменьшить вероятность возникновения ошибок.
1. Предиктивная аналитика для обнаружения аномалий
Использование машинного обучения для анализа исторических данных о платежах может помочь выявить аномалии и потенциальные проблемы еще до их возникновения. Например, можно обучить модель для прогнозирования ожидаемого количества платежей в определенный период времени. Если фактическое количество платежей значительно отклоняется от прогноза, это может указывать на проблему в системе.
# Пример использования библиотеки scikit-learn для прогнозирования количества платежей
from sklearn.linear_model import LinearRegression
import pandas as pd
# Загрузка исторических данных о платежах
data = pd.read_csv('payment_history.csv')
# Подготовка данных для обучения модели
X = data[['day_of_week', 'time_of_day']]
y = data['payment_count']
# Обучение модели линейной регрессии
model = LinearRegression()
model.fit(X, y)
# Прогнозирование количества платежей на следующий день
next_day_data = pd.DataFrame([[1, 10]], columns=['day_of_week', 'time_of_day'])
predicted_payment_count = model.predict(next_day_data)[0]
print(f'Прогнозируемое количество платежей: {predicted_payment_count}')
2. Автоматическое восстановление после сбоев
В случае возникновения сбоев в системе важно иметь механизмы автоматического восстановления. Например, если API платежной системы временно недоступен, можно автоматически переключиться на резервный API или использовать кэшированные данные для обработки платежей. Также рекомендуется использовать Circuit Breaker паттерн, чтобы предотвратить каскадные отказы.
3. Интеграция с системами мониторинга и трассировки
Для обеспечения прозрачности и управляемости системы необходимо интегрировать ее с системами мониторинга и трассировки. Это позволит отслеживать потоки данных, выявлять узкие места и быстро диагностировать проблемы. Рекомендуется использовать такие инструменты, как Prometheus, Grafana и Jaeger.
4. Использование Feature Flags
Feature Flags позволяют включать и выключать функциональность в production-среде без необходимости передеплоя. Это особенно полезно при внедрении новых функций или изменении существующих. С помощью Feature Flags можно тестировать новые функции на небольшой группе пользователей и постепенно расширять аудиторию, если все работает нормально.
5. Оптимизация запросов к базам данных
Производительность баз данных играет важную роль в скорости обработки платежей. Необходимо оптимизировать запросы к базам данных, использовать индексы и избегать избыточных данных. Также рекомендуется использовать кэширование данных, чтобы уменьшить нагрузку на базы данных.
Чек-лист: Внедрение надежной системы сверки платежей
Чтобы успешно внедрить надежную систему сверки платежей, рекомендуется следовать следующему чек-листу:
- Определите контрольные цели сверки статусов платежей.
- Составьте карту рисков, где может пойти что-то не так.
- Спроектируйте event-driven архитектуру.
- Реализуйте идемпотентные операции.
- Настройте Dead Letter Queue (DLQ).
- Внедрите мониторинг и оповещения.
- Настройте API Gateway с policy-driven маршрутизацией.
- Реализуйте retry-механизмы с экспоненциальной задержкой.
- Определите ключевые метрики для отчетности.
- Интегрируйте систему с системами мониторинга и трассировки.
- Используйте Feature Flags для управления функциональностью.
- Оптимизируйте запросы к базам данных.
- Автоматизируйте процесс восстановления после сбоев.
- Проведите тестирование системы в различных условиях.
- Обучите персонал работе с системой.
- Регулярно анализируйте данные и принимайте меры по улучшению системы.
Антипаттерны: Чего следует избегать при построении системы сверки платежей
При построении системы сверки платежей следует избегать следующих антипаттернов:
- Игнорирование ошибок. Все ошибки должны быть обработаны и зарегистрированы.
- Ручная обработка. Максимально автоматизируйте процессы. Ручная обработка увеличивает вероятность ошибок и снижает скорость.
- Отсутствие мониторинга. Мониторинг необходим для выявления проблем и предотвращения их возникновения.
- Отсутствие резервных копий. Регулярно делайте резервные копии данных.
- Недостаточное тестирование. Тестируйте систему в различных условиях, чтобы выявить возможные проблемы.
- Перегрузка системы повторными запросами. Используйте экспоненциальную задержку между повторными попытками.
- Отсутствие триажа инцидентов. Разработайте систему триажа инцидентов, чтобы быстро определять приоритетность проблем и направлять их соответствующим командам.
Пример внедрения системы сверки платежей
Предположим, что компания предоставляет услуги по онлайн-образованию и работает с несколькими платежными шлюзами. Для обеспечения надежной сверки статусов платежей компания внедрила event-driven архитектуру, где каждое изменение статуса платежа генерирует событие. Эти события отправляются в очередь сообщений, откуда их обрабатывают специальные сервисы. Для обработки ошибок используется DLQ, а для мониторинга – Prometheus и Grafana. Retry-механизмы с экспоненциальной задержкой позволяют автоматически обрабатывать временные сбои в работе платежных шлюзов. Благодаря внедрению этой системы компания смогла значительно уменьшить количество расхождений в платежах и повысить удовлетворенность клиентов.
Заключение
Построение надежной системы сверки статусов платежей – сложная задача, требующая комплексного подхода. Event-driven архитектура, идемпотентные операции, DLQ, мониторинг, retry-механизмы и другие рассмотренные в этой статье стратегии позволяют значительно повысить надежность, предсказуемость и масштабируемость системы. Не упустите возможность оптимизировать свою архитектуру и обеспечить бесперебойную работу ваших интеграций - свяжитесь с нами для консультации.


