Представьте: у вас есть developer portal, который активно используется B2B-клиентами для интеграции с вашим API. Клиенты генерируют большой объем данных, зависят от стабильности вашего API, и у вас жестко определены enterprise SLA. Внезапно, один из ключевых интеграционных потоков начинает работать медленнее, чем обычно. Клиенты жалуются, SLA под угрозой, а команды разработки и поддержки тратят время на поиск источника проблемы. Что делать?
Решение – сквозная наблюдаемость API и lineage tracking. Это позволяет отслеживать путь данных от начала и до конца, выявлять узкие места и быстро решать проблемы. А если добавить к этому AI-ассистента в developer portal, то можно автоматизировать часть рутинных задач и предоставить клиентам возможность самостоятельно находить ответы на вопросы.
В этой статье мы рассмотрим, как построить такую систему, чтобы она была полезна для команд разработки, поддержки и ваших клиентов.

Графовая модель: основа для lineage tracking
Центральным элементом системы lineage tracking является графовая модель. Она позволяет представить данные и их преобразования в виде графа, где узлы – это сущности (например, API-методы, источники данных, задачи обработки данных), а ребра – это связи между ними (например, какие данные используются каким API-методом, какие задачи преобразуют какие данные).
Связи сущностей: что в графе важно
Для эффективного lineage tracking нужно определить, какие сущности и связи будут отслеживаться. В контексте API и developer portal это могут быть:
- API-методы: какие методы используются, какие данные принимают и возвращают.
- Источники данных: откуда берутся данные, какие базы данных, очереди сообщений и т.д.
- Задачи обработки данных: какие задачи выполняются для преобразования данных (например, валидация, агрегация, фильтрация).
- Пользователи и приложения: кто и как использует API.
- СLA-соrеcards: текущее и историческое состояние SLA для конкретных потребителей API.
Связи между сущностями могут быть:
- Использование данных: какой API-метод использует какие данные.
- Преобразование данных: какая задача преобразует какие данные.
- Зависимости: какие API-методы зависят от каких источников данных.
Например, если у вас есть API-метод `get_customer_data`, который использует данные из базы данных `customers` и задачи `validate_customer_data`, то граф будет содержать узлы `get_customer_data`, `customers`, `validate_customer_data` и ребра, соединяющие их.
Geo-узлы: распределенные системы и мониторинг API
В распределенных системах, где компоненты расположены в разных географических регионах, важно учитывать geo-узлы. Это позволяет отслеживать, где именно происходят преобразования данных и возникают проблемы.
Например, если у вас есть API, развернутый в нескольких регионах, то каждый инстанс API будет отдельным geo-узлом. Это позволяет выявить, что проблема возникает только в определенном регионе, что существенно сужает область поиска.
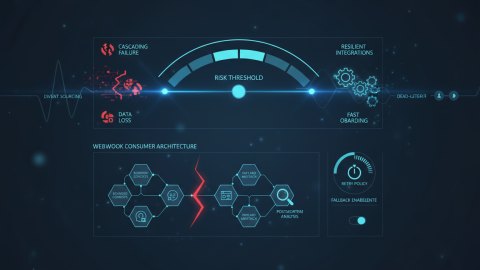
Распространение риска: как lineage tracking помогает предотвратить проблемы
Lineage tracking позволяет отслеживать, как изменения в одной части системы могут повлиять на другие части. Например, если изменяется схема базы данных, то это может повлиять на API-методы, которые используют эти данные. Lineage tracking позволяет выявить эти зависимости и предотвратить проблемы.
Пример: Предположим, вы планируете обновить версию базы данных, используемой вашим API. Без lineage tracking вы можете не знать, какие API-методы зависят от этой базы данных. С lineage tracking вы можете легко увидеть, что `get_customer_data`, `update_customer_data` и `delete_customer_data` используют эту базу данных. Вы можете протестировать эти методы после обновления базы данных, чтобы убедиться, что они работают правильно.
Чеклист предотвращения проблем с помощью lineage tracking:
- Определите ключевые сущности и связи в вашей системе.
- Создайте графовую модель, отражающую эти сущности и связи.
- Используйте lineage tracking для отслеживания изменений и выявления потенциальных проблем.
- Автоматизируйте процесс тестирования зависимых компонентов после внесения изменений.
- Интегрируйте lineage tracking с системой мониторинга и оповещения.
Более подробно вопросы надежности API описаны в статье Playbook по надежности API: Tech Due Diligence для интеграций CRM и ERP.
Визуализация и анализ данных: AI-ассистент для developer portal
Lineage tracking создает большой объем данных, который необходимо визуализировать и анализировать. Здесь на помощь приходит AI-ассистент для developer portal. Он может предоставлять пользователям (разработчикам, командам поддержки) информацию о lineage в удобном формате.
Пример:
Предположим, клиент сообщает о проблеме с API-методом `get_order_status`. AI-ассистент может предоставить следующую информацию:
- Lineage-граф, показывающий, какие источники данных и задачи обработки данных используются `get_order_status`.
- Метрики производительности для каждого компонента в lineage-графе.
- Информация о последних изменениях в компонентах lineage-графа.
- Список известных проблем, связанных с компонентами lineage-графа.
Это позволяет команде поддержки быстро определить причину проблемы и предложить решение.
Шаги внедрения AI-ассистента в developer portal:
- Сбор и анализ данных: Соберите данные о lineage, метрики производительности, логи и другую релевантную информацию.
- Построение моделей: Разработайте модели машинного обучения для анализа данных и выявления аномалий и проблем.
- Интеграция с developer portal: Интегрируйте AI-ассистента с developer portal, чтобы пользователи могли получать информацию о lineage и проблемах.
- Обучение и улучшение: Постоянно обучайте и улучшайте AI-ассистента на основе обратной связи от пользователей.
Итоги: сквозная наблюдаемость и lineage tracking как конкурентное преимущество
Сквозная наблюдаемость API и lineage tracking, в сочетании с AI-ассистентом в developer portal, – это мощный инструмент для обеспечения стабильности и надежности API, соблюдения enterprise SLA и снижения операционных издержек. Это позволяет:
- Быстро выявлять и решать проблемы.
- Предотвращать проблемы до того, как они повлияют на клиентов.
- Автоматизировать рутинные задачи.
- Предоставлять клиентам возможность самостоятельно находить ответы на вопросы.
Внедрение такой системы требует инвестиций, но отдача от нее может быть огромной. Это не только улучшает качество обслуживания клиентов, но и позволяет командам разработки и поддержки работать более эффективно. Более подробно вопросы policy-driven маршрутизации описаны в статье Playbook миграции API Gateway на Policy-Driven маршрутизацию для B2B: от разработки до production.
Хотите построить надежную и отказоустойчивую систему для вашего B2B API? Обратитесь к нам за консультацией, и мы поможем вам разработать и внедрить решение, которое лучше всего подходит для ваших потребностей.
Связанные материалы
Рекомендации по архитектуре lineage tracking системы
При проектировании системы lineage tracking важно учитывать несколько ключевых аспектов, чтобы обеспечить ее эффективность и масштабируемость:
-
Выбор технологии хранения графа. Существует несколько вариантов, включая графовые базы данных (например, Neo4j) и реляционные базы данных с графовыми расширениями. Выбор зависит от масштаба и сложности данных, а также от требований к производительности.
-
Автоматизация сбора lineage данных. В идеале процесс сбора lineage должен быть автоматизирован. Это можно сделать с помощью инструментов мониторинга, перехвата вызовов API, анализа логов и т.д. Ручной сбор lineage данных подвержен ошибкам и не масштабируется.
-
Интеграция с системой управления метаданными. Lineage данные должны быть интегрированы с системой управления метаданными, чтобы обеспечить полноту и согласованность информации. Это позволяет пользователям легко находить и понимать lineage для любого объекта данных.
-
Поддержка различных типов данных. Система lineage tracking должна поддерживать различные типы данных, включая структурированные данные, неструктурированные данные, потоковые данные и т.д.
-
Масштабируемость и производительность. Система lineage tracking должна быть масштабируемой и обеспечивать высокую производительность, чтобы обрабатывать большие объемы данных в реальном времени.
Антипаттерны при внедрении lineage tracking
При внедрении lineage tracking важно избегать следующих антипаттернов:
- Ручной сбор lineage данных. Этот процесс подвержен ошибкам и не масштабируется. Старайтесь максимально автоматизировать процесс сбора lineage данных.
- Отсутствие интеграции с системой управления метаданными. Это приводит к фрагментации информации и затрудняет поиск и понимание lineage данных.
- Игнорирование неструктурированных данных. Неструктурированные данные (например, логи, документы, изображения) также могут содержать важную информацию о lineage.
- Недостаточная масштабируемость. Система lineage tracking должна быть масштабируемой, чтобы обрабатывать большие объемы данных в реальном времени.
- Отсутствие мониторинга и оповещения. Необходимо мониторить систему lineage tracking и оповещать о любых проблемах (например, об отсутствии данных, ошибках в сборе данных и т.д.).
Пример внедрения: lineage tracking для API обработки платежей
Рассмотрим пример внедрения lineage tracking для API обработки платежей. Цель – обеспечить сквозную наблюдаемость и lineage tracking, чтобы AI-ассистент мог помогать командам разработки и поддержки быстро выявлять и решать проблемы.
- Определение ключевых сущностей:
- API-методы: `process_payment`, `refund_payment`, `get_transaction_status`.
- Источники данных: база данных транзакций, платежные шлюзы, системы fraud detection.
- Задачи обработки данных: валидация платежа, маршрутизация платежа, обработка возврата.
- Создание графовой модели:
- Узлы: API-методы, источники данных, задачи обработки данных.
- Ребра: `process_payment` использует данные из базы данных транзакций, `validate_payment` преобразует данные платежа, `process_payment` зависит от платежного шлюза.
- Автоматизация сбора lineage данных:
- Использование APM (Application Performance Monitoring) инструментов для перехвата вызовов API и отслеживания передачи данных.
- Анализ логов для выявления связей между компонентами.
- Интеграция с базой данных транзакций для отслеживания lineage данных на уровне данных.
- Интеграция с AI-ассистентом:
- Предоставление AI-ассистенту доступа к графу lineage.
- Обучение AI-ассистента выявлять аномалии и проблемы на основе lineage данных.
- Возможность для пользователей задавать вопросы AI-ассистенту о lineage в удобном формате. Например, "Какие данные использует API-метод `process_payment`?", "Какие компоненты могут быть затронуты, если изменить схему базы данных транзакций?".
В результате, если клиент сообщает о проблеме с API-методом `process_payment`, AI-ассистент может предоставить следующую информацию:
- Lineage-граф, показывающий все компоненты, используемые `process_payment`.
- Метрики производительности для каждого компонента.
- Информацию о последних изменениях в компонентах.
- Список известных проблем, связанных с компонентами.
Это позволяет команде поддержки быстро определить причину проблемы (например, проблема с платежным шлюзом) и предложить решение.