В мире B2B, где критически важна надежность и безопасность данных, Event-Driven Automation Pipelines (EDA) становятся неотъемлемой частью инфраструктуры. Они позволяют автоматизировать сложные процессы, обеспечивать сквозную наблюдаемость и оперативно реагировать на возникающие события. Особенно это актуально для edge-cases биллинга и масштабирования.
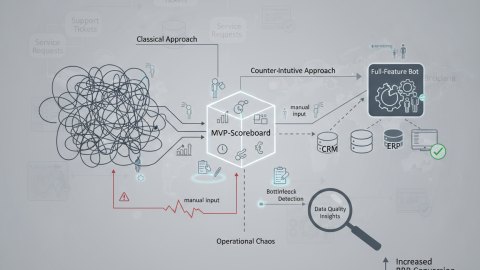
От MVP к production
Создание Event-Driven Automation Pipelines начинается с определения минимально жизнеспособного продукта (MVP). На этом этапе важно:
- Определить ключевое бизнес-событие. Например, "Оплата счета зарегистрирована".
- Спроектировать простой пайплайн обработки. Это может быть, например, запись события в базу данных и отправка уведомления в систему биллинга.
- Внедрить базовую наблюдаемость. Мониторинг количества событий и времени их обработки.
На MVP этапе важно проверить ключевые гипотезы и убедиться, что EDA решает поставленную задачу. От MVP легко перейти к полноценному production развертыванию, если заложить правильные архитектурные принципы с самого начала.
Базовый флоу
Рассмотрим пример простого пайплайна для обработки событий оплаты счетов:
- Источник события: Система приема платежей генерирует событие "Оплата счета зарегистрирована".
- Брокер сообщений: Событие попадает в брокер сообщений (например, Kafka, RabbitMQ или Pulsar).
- Потребитель 1: Сервис биллинга получает событие и обновляет статус счета.
- Потребитель 2: Сервис аналитики получает событие и агрегирует данные для отчетов.
- Потребитель 3: Сервис уведомлений получает событие и отправляет уведомление пользователю об успешной оплате.
Чеклист для базового флоу:
- Удостоверьтесь, что каждое событие имеет уникальный идентификатор.
- Реализуйте механизм повторной отправки событий в случае сбоев. См. Безопасная Rollback-стратегия для Webhook-интеграций.
- Определите формат сообщений (например, JSON Schema).
- Обеспечьте idempotency операций: потребители должны обрабатывать одно и то же событие несколько раз без негативных последствий.
Масштабирование
С ростом бизнеса необходимо масштабировать Event-Driven Automation Pipelines. Важные аспекты:
- Горизонтальное масштабирование потребителей. Добавление новых экземпляров сервисов-потребителей для обработки большего количества событий.
- Разделение топиков сообщений. Использование разных топиков для разных типов событий или разных потребителей, чтобы избежать "узких мест".
- Оптимизация пропускной способности брокера сообщений. Увеличение количества партиций и реплик.
На этапе масштабирования появляется необходимость в более продвинутых инструментах мониторинга и управления. Следует внедрить инструменты, позволяющие отслеживать производительность каждого компонента пайплайна и оперативно реагировать на возникающие проблемы.
Отказоустойчивость
Отказоустойчивость – ключевой фактор надежности Event-Driven Automation Pipelines. Необходимые меры:
- Резервирование брокера сообщений. Использование кластеров брокеров с автоматическим переключением в случае сбоя.
- Изоляция потребителей. Каждый потребитель должен быть изолирован от других, чтобы сбой одного потребителя не влиял на работу других.
- Dead Letter Queue (DLQ). События, которые не удалось обработать после нескольких попыток, должны быть помещены в DLQ для дальнейшего анализа и обработки вручную.
- Circuit Breaker Pattern. Предотвращает лавинообразные отказы, отключая проблемные потребители и разрывая цепь вызовов.
Важно помнить, что отказоустойчивость напрямую влияет на SLA. См. Сквозная наблюдаемость API и lineage tracking для SLA.
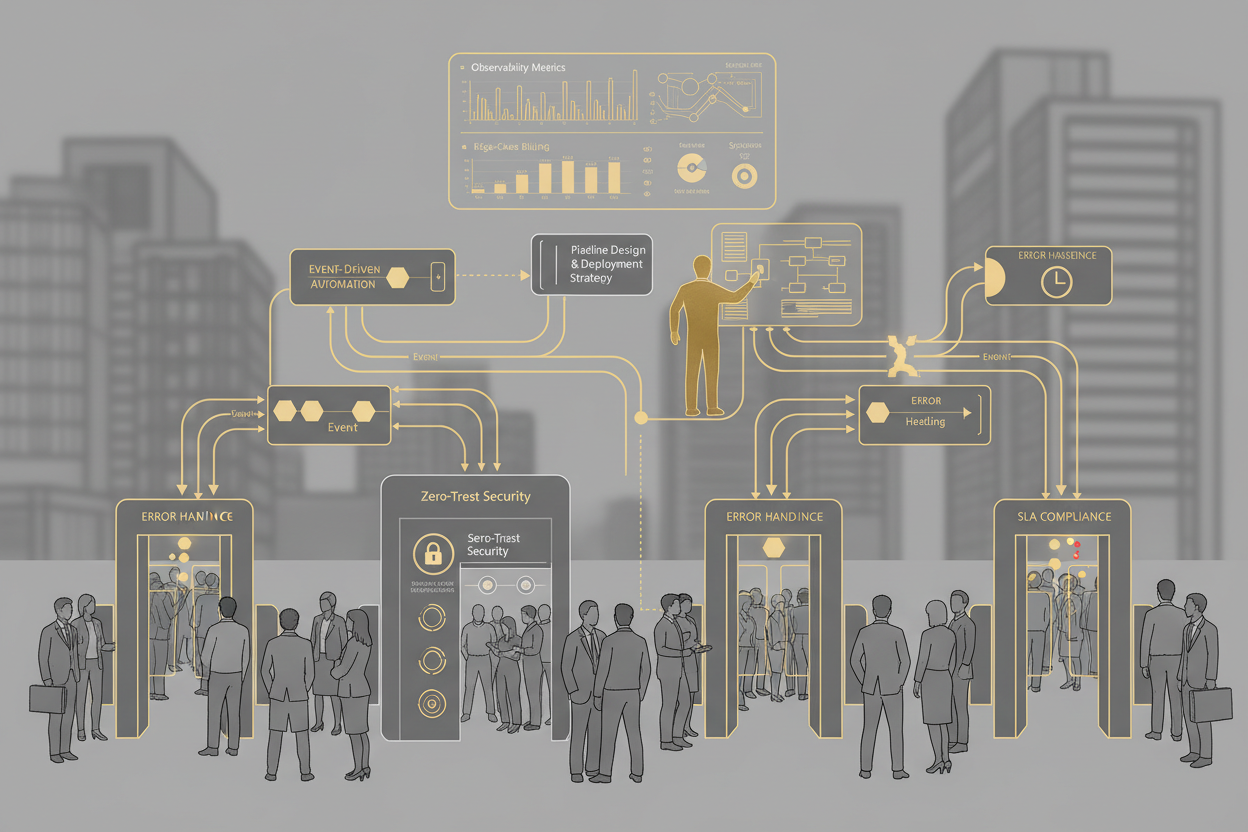
Enterprise Security и Observability Matrix
| Уровень | Метрики Observability | Security Controls |
|---|---|---|
| Брокер сообщений | Задержка сообщений, пропускная способность, количество необработанных сообщений, ошибки | Авторизация и аутентификация, шифрование трафика, ACL |
| Потребители | Время обработки событий, использование ресурсов (CPU, память), количество ошибок | Изоляция процессов, анализ уязвимостей, защита от инъекций |
| API | Время ответа, количество запросов, процент ошибок | OWASP, Rate limiting, защита от DDoS |
| БД | Время запроса, количество запросов, использование ресурсов | Шифрование данных, маскирование данных, аудит доступа |
SLA
Определение и соблюдение соглашений об уровне обслуживания (SLA) – критически важная задача для B2B. Event-Driven Automation Pipelines должны соответствовать определенным требованиям по доступности, времени обработки и целостности данных.
Пример SLA metrics:
- Доступность. Пайплайн должен быть доступен 99.99% времени.
- Время обработки. 95% событий должны быть обработаны в течение 1 секунды.
- Целостность данных. Не должно быть потери или искажения данных.
Для достижения SLA необходимо тщательно мониторить каждый компонент пайплайна, оперативно реагировать на возникающие инциденты и проводить регулярные аудиты безопасности.
Вывод
Event-Driven Automation Pipelines – мощный инструмент для автоматизации бизнес-процессов, обеспечения безопасности и наблюдаемости. Правильное проектирование, масштабирование и отказоустойчивость – ключевые факторы успеха. Тщательный мониторинг и соблюдение SLA – залог надежной и предсказуемой работы всей системы.
Внедрение Event-Driven Automation Pipelines – сложная задача, требующая экспертизы в различных областях. Если вам требуется помощь в проектировании, разработке и внедрении таких пайплайнов, обратитесь к нашим специалистам. Оставьте заявку на консультацию, и мы поможем вам создать надежную и эффективную систему.
Связанные материалы
Продвинутая обработка ошибок и retry-policies
Обработка ошибок занимает центральное место в архитектуре Event-Driven Automation Pipelines. Недостаточно просто поместить сообщение в DLQ. Необходимо внедрить комплексную систему, которая автоматически пытается исправить ошибки и только потом, если это невозможно, эскалирует проблему.
Антипаттерны обработки ошибок:
- Слепое помещение в DLQ: Отправка сообщений в DLQ без анализа и попыток восстановления.
- Неограниченные retry: Бесконечные попытки обработки одного и того же сообщения, приводящие к блокировке ресурсов.
- Игнорирование контекста ошибки: Отсутствие информации о причине сбоя, что затрудняет диагностику.
Пример retry-policy с экспоненциальной задержкой и jitter:
- Первая попытка: сразу после получения сообщения.
- Вторая попытка: через 1 секунду +/- 100 миллисекунд (jitter).
- Третья попытка: через 3 секунды +/- 500 миллисекунд.
- Четвертая попытка: через 9 секунд +/- 1 секунду.
- Пятая попытка: через 27 секунд +/- 2 секунды.
- Если после пятой попытки сообщение не обработано, оно помещается в DLQ с подробной информацией об ошибках и контексте.
Jitter добавляет случайность в задержки, предотвращая одновременные повторные попытки и снижая вероятность "лавинообразного отказа".
Чеклист для обработки ошибок:
- Реализовать retry-policy с экспоненциальной задержкой и jitter.
- Обеспечить возможность настройки retry-policy для разных типов событий.
- Регистрировать все ошибки, включая информацию о контексте и причинах.
- Создать систему мониторинга DLQ для оперативного реагирования на проблемы.
- Автоматизировать процесс анализа DLQ и восстановления сообщений, где это возможно.
Security на всех уровнях пайплайна
В Event-Driven Automation Pipelines безопасность должна быть встроена на каждом уровне, а не добавляться как afterthought. Это включает в себя защиту брокера сообщений, потребителей, API и баз данных.
Примеры security-controls:
- Брокер сообщений: TLS шифрование трафика, аутентификация и авторизация на основе ролей (RBAC), ACL для ограничения доступа к топикам.
- Потребители: Изоляция процессов с использованием контейнеров, сканирование на уязвимости, защита от common injection vulnerabilities.
- API: Аутентификация и авторизация (OAuth 2.0, JWT), rate limiting для защиты от DDoS-атак, валидация входных данных.
- Базы данных: Шифрование данных в состоянии покоя и при передаче, маскирование конфиденциальных данных, аудит доступа. Подробнее см. Secrets & configuration management: tech due diligence observability matrix.
Чеклист для обеспечения безопасности:
- Внедрить security controls на каждом уровне пайплайна.
- Регулярно проводить сканирование на уязвимости и penetration testing.
- Разработать план реагирования на инциденты безопасности.
- Обучать разработчиков принципам безопасной разработки.
- Автоматизировать security checks в CI/CD pipeline.
Observability: за пределами базовых метрик
Observability – это не только мониторинг CPU и памяти. Это возможность понимать внутреннее состояние системы на основе внешних данных. В Event-Driven Automation Pipelines это означает отслеживание не только базовых метрик, но и логики бизнес-процессов.
Примеры продвинутых метрик observability:
- Количество успешных/неуспешных транзакций биллинга.
- Время обработки разных типов платежей.
- Задержка между генерацией события и его обработкой.
- Количество сообщений в DLQ по типам ошибок.
- Correlation ID для отслеживания событий в разных сервисах.
Чеклист для внедрения Observability:
- Определить ключевые бизнес-метрики, которые необходимо отслеживать.
- Внедрить centralized logging с correlation ID для отслеживания событий.
- Использовать distributed tracing для анализа производительности и узких мест.
- Настроить alerts на основе аномалий в метриках.
- Создать dashboards для визуализации данных и анализа трендов.
Тестирование event-driven систем
Тестирование event-driven систем представляет собой уникальные сложности по сравнению с традиционными монолитными приложениями. Необходимо тестировать не только отдельные компоненты, но и их взаимодействие в условиях асинхронности и распределенности.
Типы тестов:
- Unit-тесты: Тестирование отдельных сервисов-потребителей и продюсеров.
- Интеграционные тесты: Тестирование взаимодействия между сервисами через брокер сообщений.
- E2E-тесты: Тестирование всего пайплайна целиком, от генерации события до конечного результата.
- Chaos engineering: Имитация отказов и сбоев для проверки отказоустойчивости системы.
Чеклист для тестирования:
- Написать unit-тесты для каждого сервиса.
- Реализовать интеграционные тесты с использованием mock-брокера сообщений.
- Автоматизировать E2E-тесты для проверки бизнес-логики.
- Внедрить инструменты chaos engineering для проверки отказоустойчивости.
- Регулярно проводить нагрузочное тестирование для определения пропускной способности системы.
Заключение
Создание надежной и эффективной Event-Driven Automation Pipeline для edge cases биллинга – задача, требующая комплексного подхода. Необходимо учитывать множество факторов, включая обработку ошибок, безопасность, observability и тестирование. Однако, при правильном подходе, такая система может значительно повысить эффективность бизнеса, снизить риски и обеспечить соответствие SLA.